Empower LLM Pipeline
Streamline your AI model lifecycle from data to deployment with our private LLM platform.
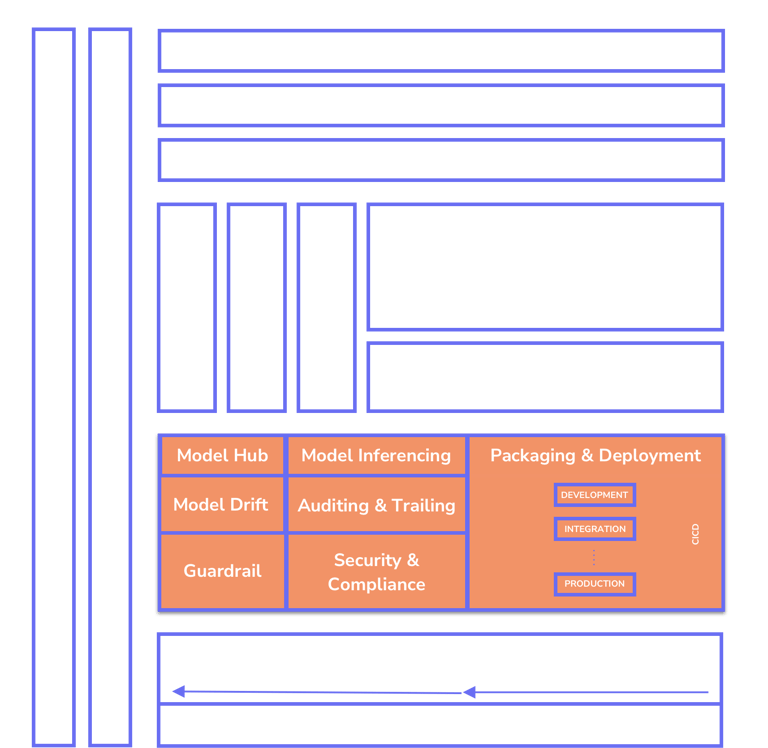
We value microservice architecture and have built our application stack based on this framework. Once model inferences are built and ready to be used, we containerize the models and inferences using wrappers, then upload them to model hub repositories for deployment. Deployments are carried out within the Kubernetes cluster, allowing us to manage the high availability and resiliency of the API development. We utilize a CI/CD pipeline on GitLab or GitHub to deploy and validate the application stack across development, test, staging, and production environments. For production and disaster recovery (DR) environments, we provide various deployment strategies such as blue-green deployment, A/B testing, and canary releases.
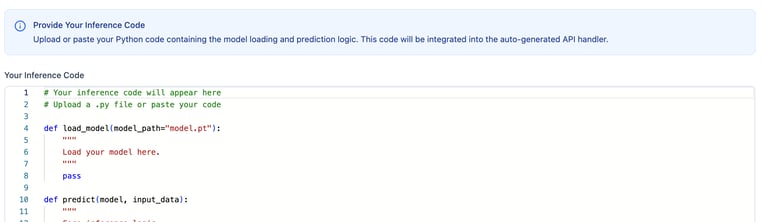
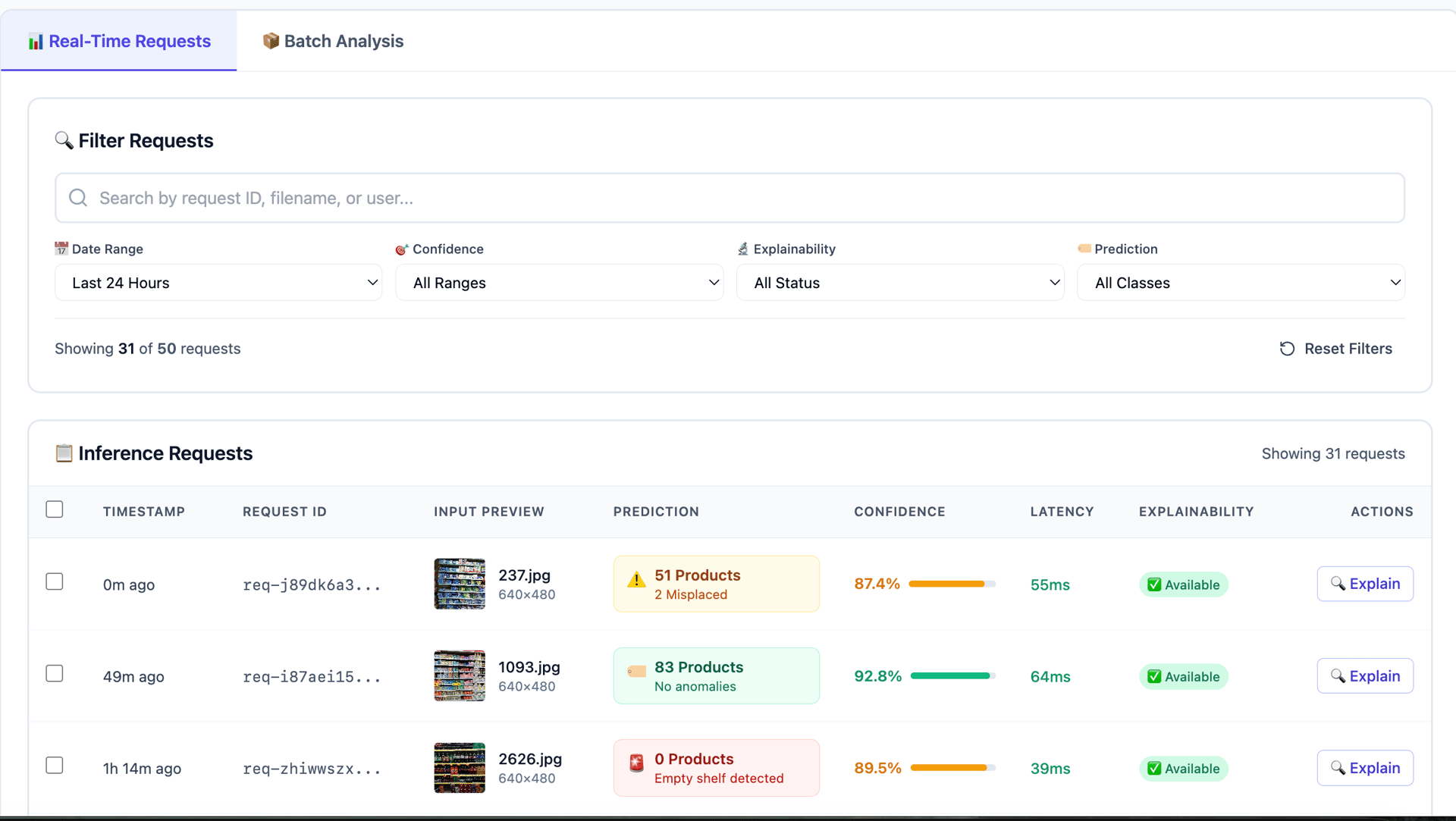
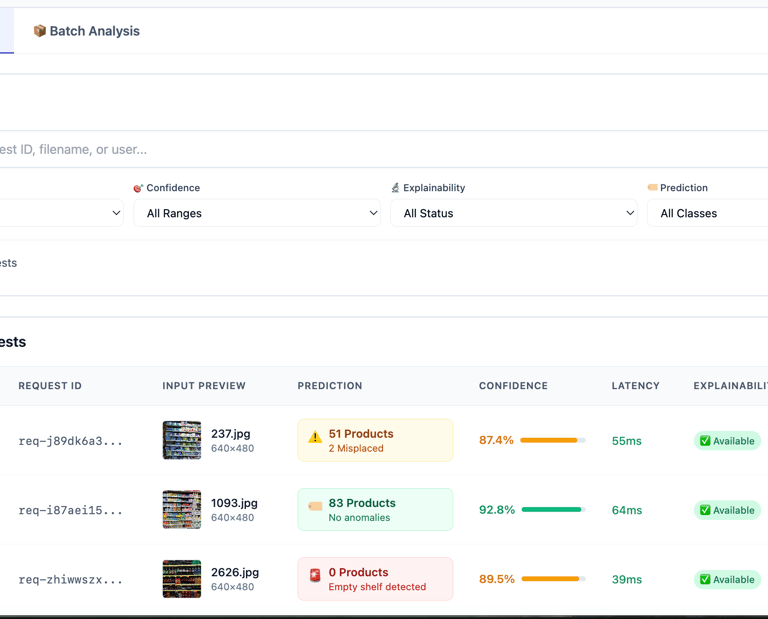
Model Inferencing
Inferencing is one of the important steps post-training. We select the fine-tuned model metrics at this step. Most LLM projects will utilize the RAG technique for modeling. Once the wrapper is finalized and evaluated by the AI engineers, it will be packaged and pushed as a Docker image to our repository.
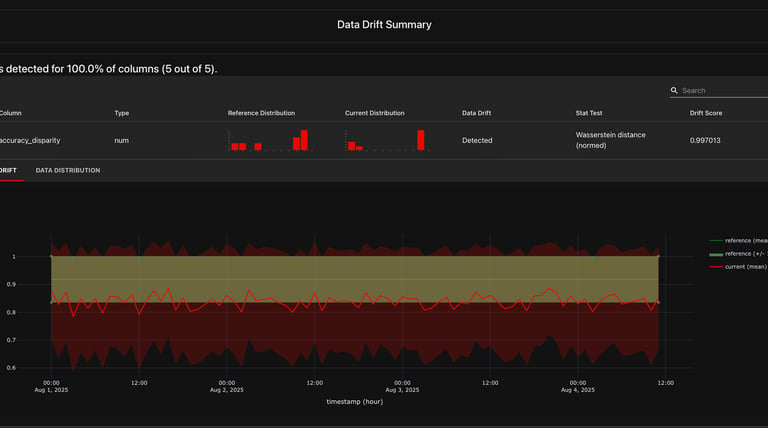
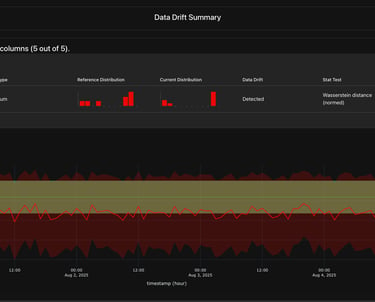
Model Drift and Observability
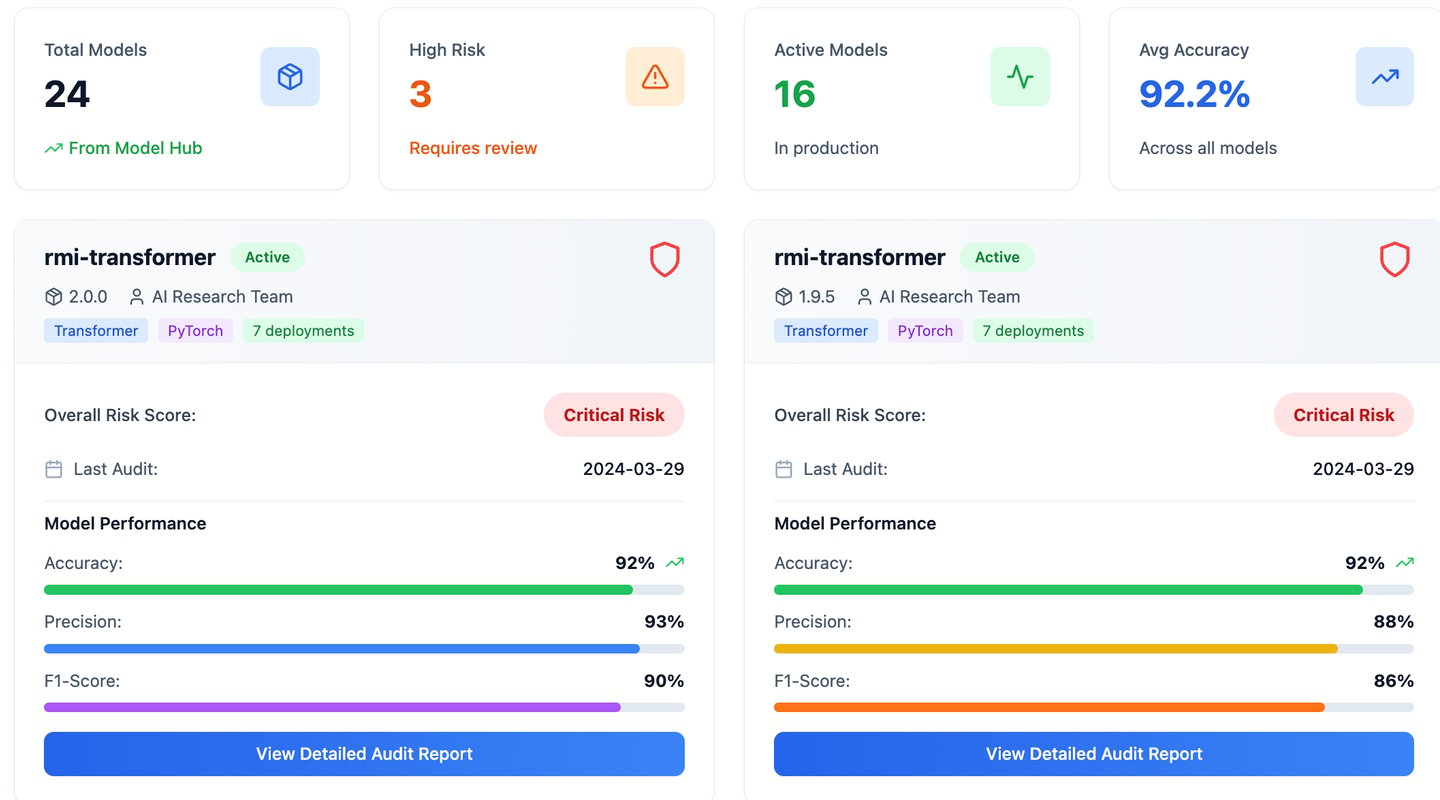
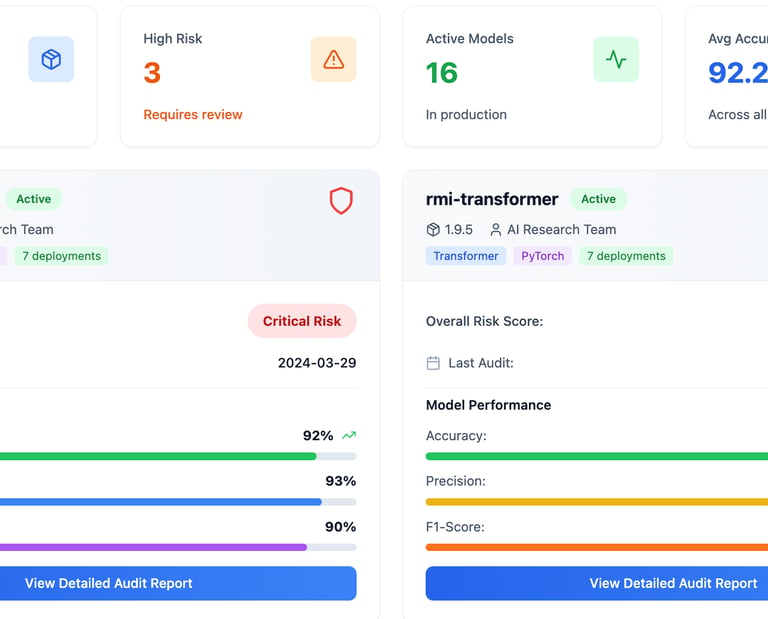
We provide comprehensive model observability metrics by automating the monitoring and analysis of models in production. Our solution captures real-time telemetry, including performance metrics like latency, accuracy, throughput, and resource utilization, alongside data distribution patterns. By leveraging advanced drift detection algorithms, we automatically identify and alert on data drift, concept drift, or deviations from expected behavior during runtime. This enables our platform to pinpoint the exact causes of performance degradation or anomalies, empowering businesses to take corrective actions promptly. Our automated observability framework ensures reliable, transparent, and high-performing models with minimal manual intervention.
Auditing and Trailing
We automate auditing and tracking within the LLMOps pipeline to ensure robust post-training model management. Our solution records a comprehensive trail of model activities, including versioning, training data lineage, hyperparameters, and deployment configurations, providing end-to-end transparency. This allows organizations to audit model performance, detect compliance issues, and verify that models align with regulatory and ethical standards. By automating tracking, we make it easy to reproduce training experiments, analyze model behavior in production, and identify root causes of performance deviations or failures. Our platform ensures accountability, reliability, and continuous improvement of large language models while minimizing manual effort.
Model Inference & Deployment
Security and compliance are integral to the LLMOps pipeline, ensuring that large language models (LLMs) operate safely, ethically, and in alignment with regulatory standards. Our company provides this as a service by implementing robust measures such as role-based access control, secure data encryption, and authentication protocols to safeguard sensitive data throughout the model lifecycle. We automate compliance checks to ensure adherence to GDPR, HIPAA, and other regulatory frameworks, while continuously monitoring for vulnerabilities and unauthorized access. Our platform also provides detailed audit logs, policy enforcement, and real-time alerts for potential security breaches or non-compliance issues. By embedding security and compliance into every stage of the LLMOps pipeline, we enable businesses to deploy and manage LLMs with confidence, reducing risk and ensuring trustworthiness.
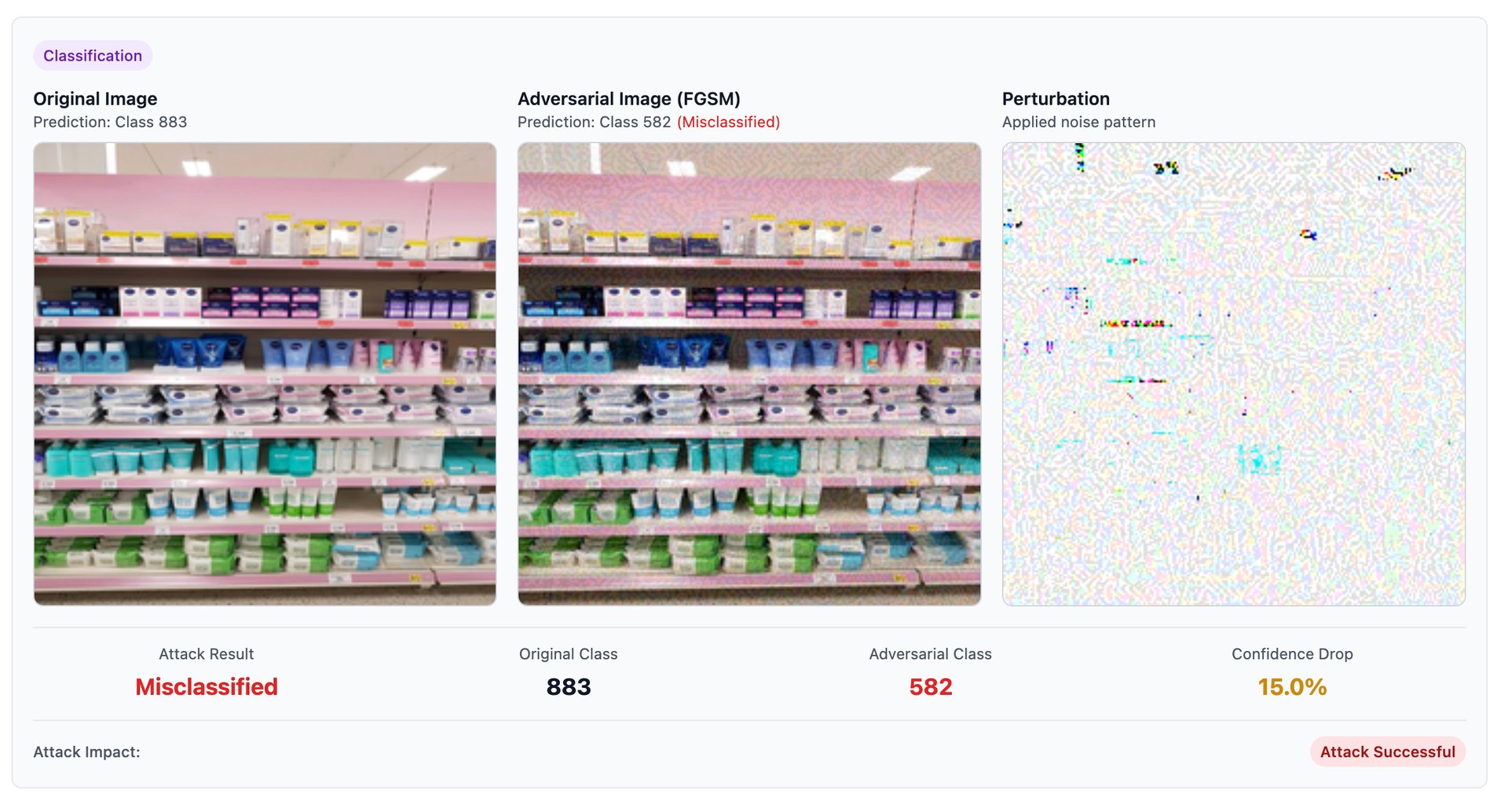
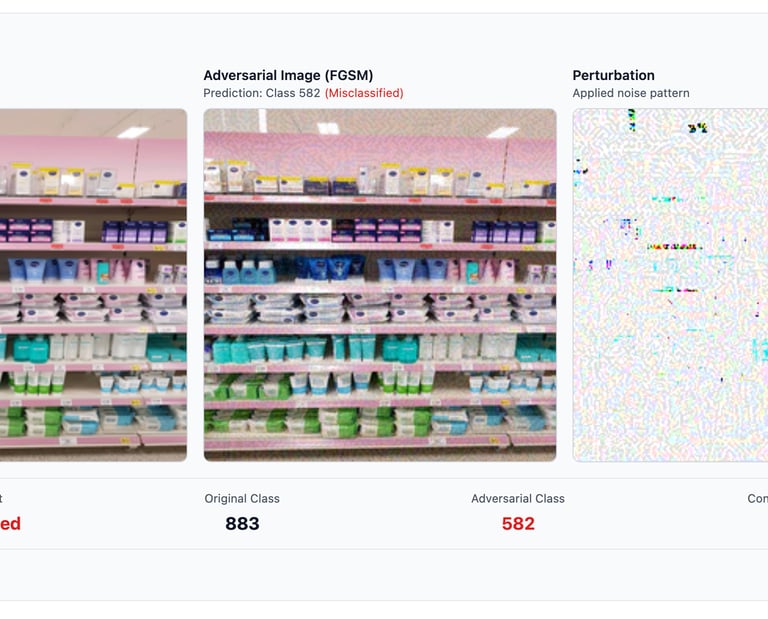
Security and Compliance
Guardrail and Responsible AI
As an LLMOps pipeline company, we integrate robust guardrails to ensure that model outputs comply with governance policies and responsible AI standards. Our solution enforces predefined policies to monitor and control the content generated by models. If the output violates these policies, it is blocked, and a modified, compliant response is provided to the user. Our system includes mechanisms to manage denied topics, ensuring the model avoids generating responses on restricted subjects as defined by organizational or ethical guidelines. We also implement responsible AI policies to uphold fairness, transparency, and accountability. Content filters actively detect and block harmful or inappropriate content, including hate speech, insults, sexual content, violence, misconduct, and prompt attacks. Additionally, we provide PII redaction to safeguard sensitive personal information and a word filter to avoid specific terms such as profanity. These automated guardrails protect users, maintain ethical standards, and ensure the safe and trustworthy operation of AI systems.
AI catalysts are essential for every data-driven company
Unlock the full potential of shipping secure AI products
Driving innovation with AI for global business excellence
Thunder AI Inc. © 2026. All rights reserved.

LLMOPS Platform