Empower LLM Pipeline
Streamline your AI model lifecycle from data to deployment with our private LLM platform.
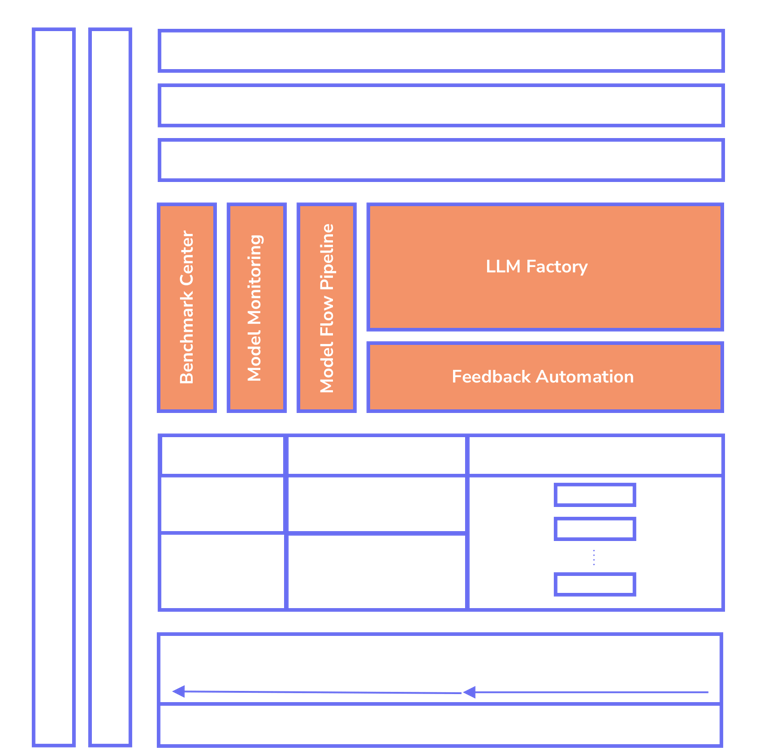
LLM Factory
LLM Factory begins with LLM model building, supporting various architectural patterns such as prompt engineering, RAG, fine-tuning, and pre-training existing models. Developers can select these patterns based on the dataset size and LLM models they wish to use. We assist developers in finding the best-performing models on Hugging Face that meet their generative AI requirements (any-to-any models), with the option to bring their own LLM models as well.
Our platform leverages state-of-the-art transformer-based fine-tuning approaches, significantly reducing computational and storage costs. We provide all the utilities AI engineers need for their use cases. For instance, for question answering or semantic search, we offer free and optimized embeddings and vector stores. For prompt engineering, we utilize all in-context learning best practices for prompt execution and analytics within a streamlined design.
In summary, LLM Factory equips developers with the tools and flexibility to build, fine-tune, and deploy high-performing LLM models efficiently, ensuring they can meet diverse AI requirements with reduced costs and enhanced capabilities.
Benchmark Center
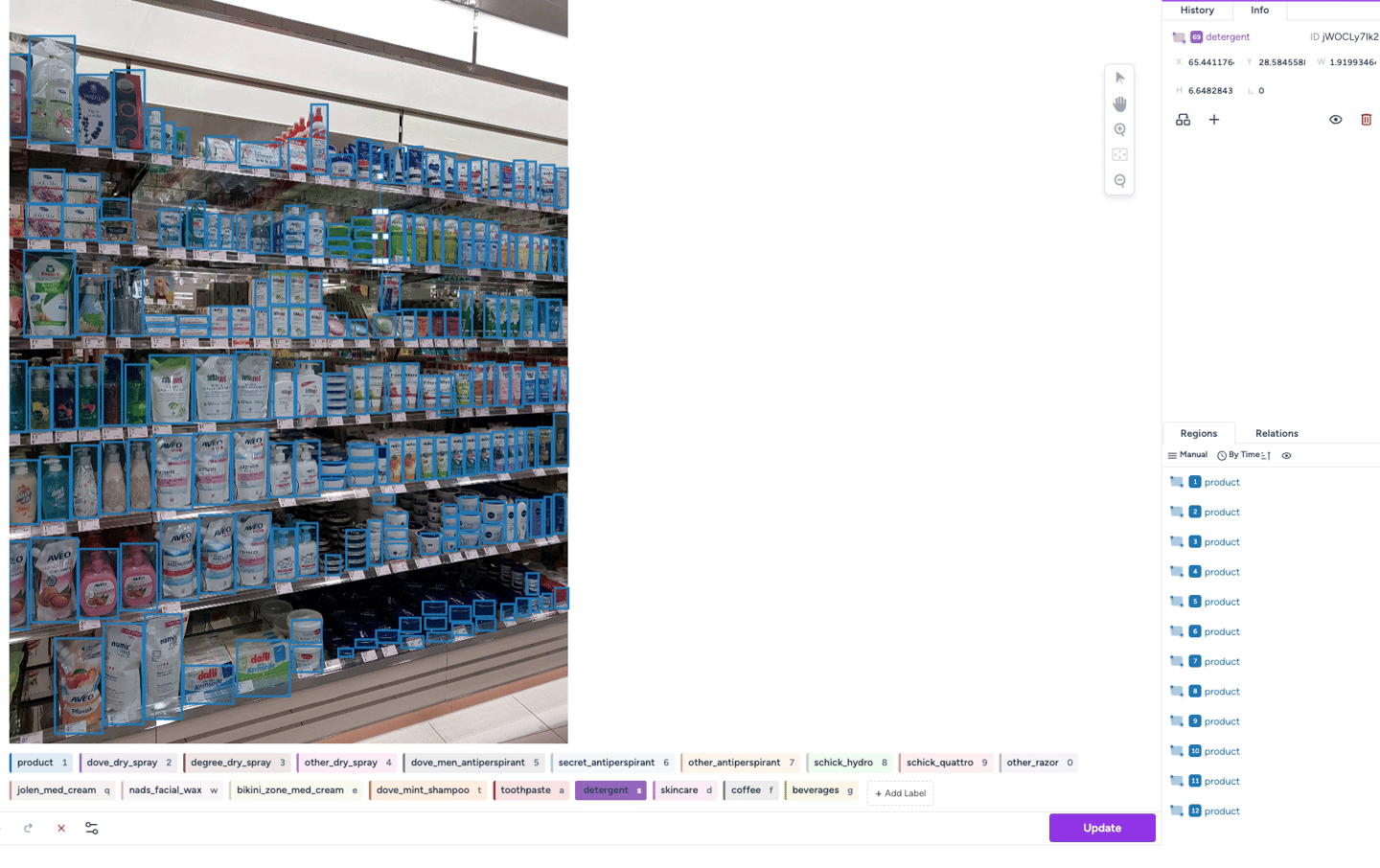
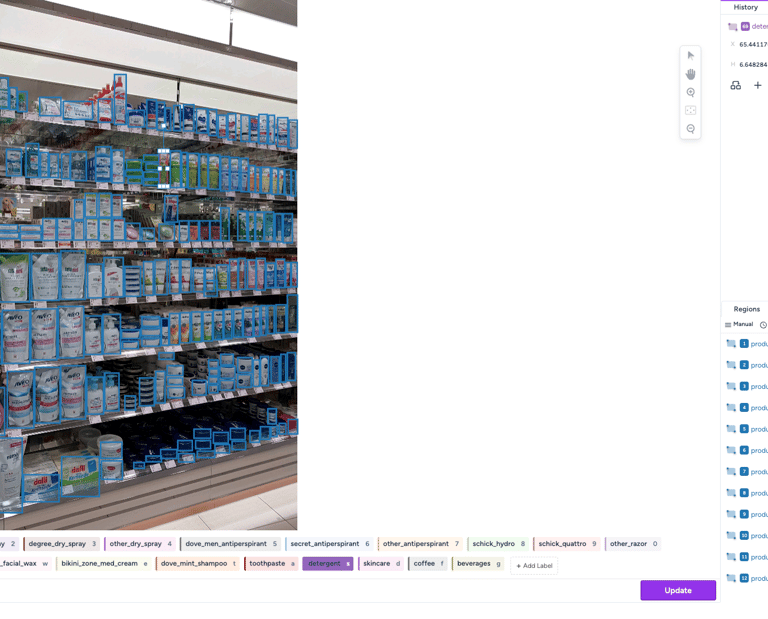
Throughout the LLM factory pipeline, various model metrics are captured. We identify the use case and collect more than 40 metrics to ensure the model quality, such as accuracy, BLEU, perplexity, SPICE, and others.
Continuous Feedback Automation
We help users evaluate the quality of model responses by providing different scoring functions tailored to various use cases. Our automated input and output ranking and rating process is trustworthy and leverages advanced annotation techniques to quantify results accurately.
This data is used as comparison data, and our automation continuously trains the model in a learning fashion to enhance performance until the desired criteria are met
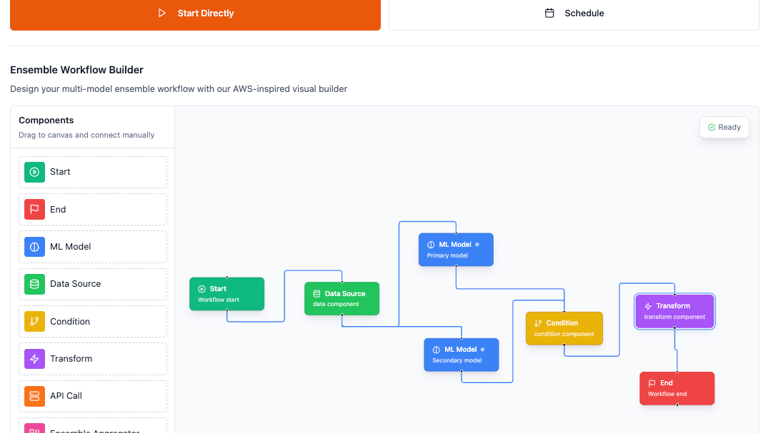
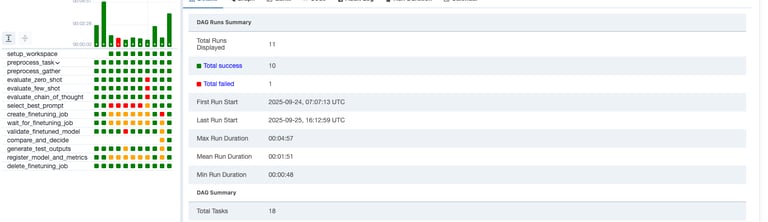
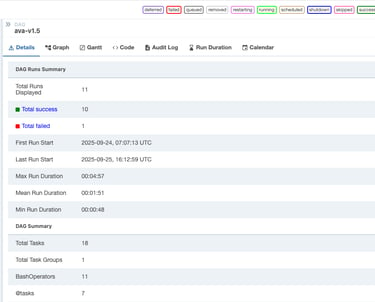
Model Flow Pipeline
Once the data is ingested and preprocessed for training, and the model, training scripts, and configurations are set for fine-tuning or full training, our system converts the pipeline into a Directed Acyclic Graph (DAG). This transformation enables high levels of automation and parallelization, significantly accelerating the model development flow—boosting training speeds by up to 50x. The workflow is structured into discrete tasks, ensuring efficient execution and resource utilization. Additionally, our system maintains stateful job management, meaning that if a task fails, the process resumes from the last successful checkpoint, eliminating the need to restart the entire pipeline and ensuring seamless fault tolerance.
Model Monitoring
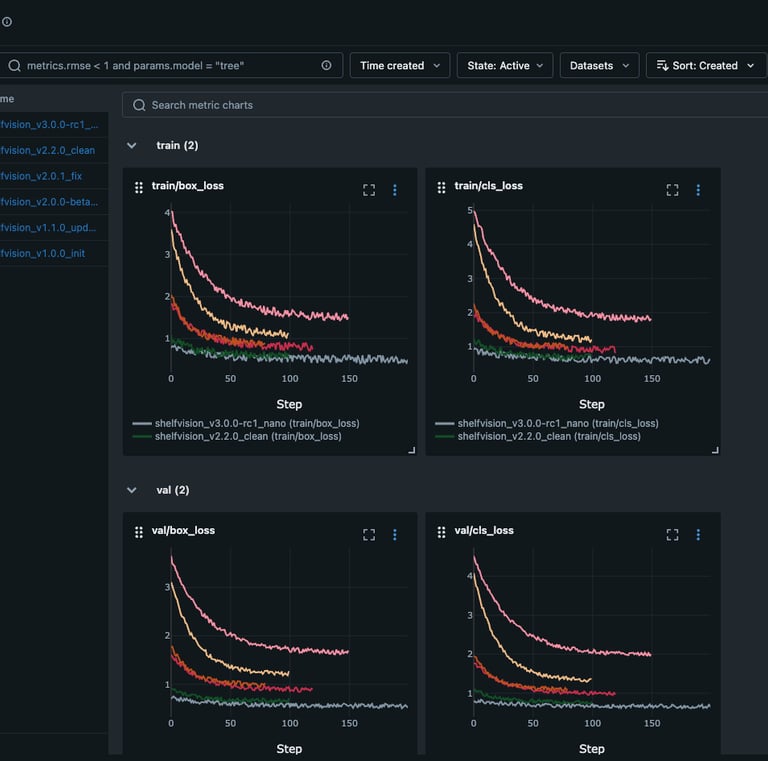
Our Model Monitoring Service provides continuous tracking and analysis of key LLM training metrics to ensure optimal performance, stability, and efficiency. By embedding monitoring agents directly into the training code, we automatically capture critical indicators such as loss trends, perplexity, accuracy, validation performance, GPU/TPU utilization, memory consumption, and inference latency. Our solution also detects bias, toxicity, and fairness metrics to ensure responsible AI deployment. These insights are visualized through a customized dashboard, giving AI engineers and data scientists real-time visibility into model behavior. The monitoring system enables teams to profile training scripts, optimize performance, and detect inefficiencies, while also generating detailed reports for higher management. Additionally, the collected data helps enhance future training batches, improving overall model accuracy and efficiency. Our solution ensures that enterprises can track, refine, and govern AI models effectively at every stage of the pipeline.
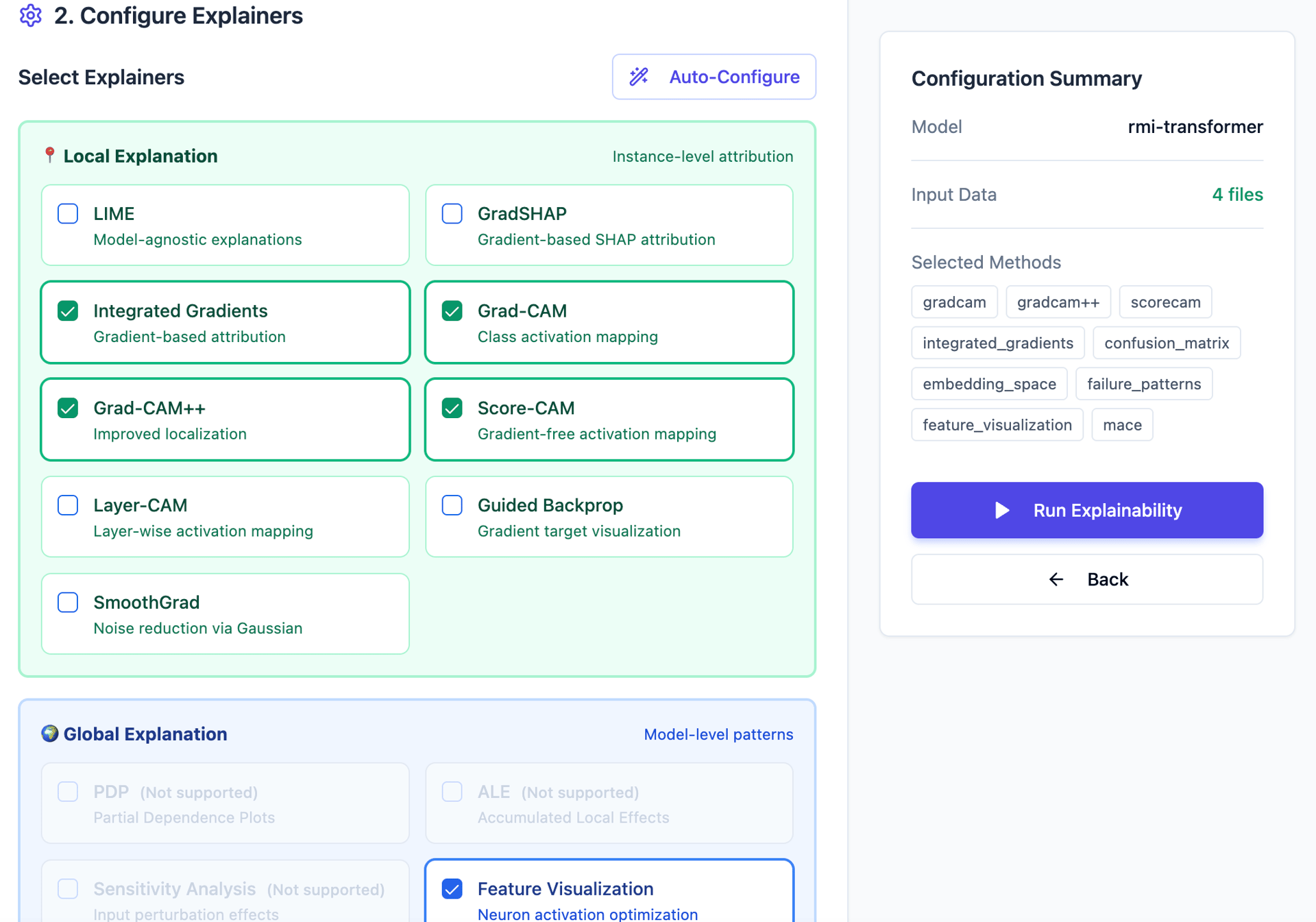
AI catalysts are essential for every data-driven company
Unlock the full potential of shipping secure AI products
Driving innovation with AI for global business excellence
Thunder AI Inc. © 2026. All rights reserved.

LLMOPS Platform