Empower LLM Pipeline
Streamline your AI model lifecycle from data to deployment with our private LLM platform.
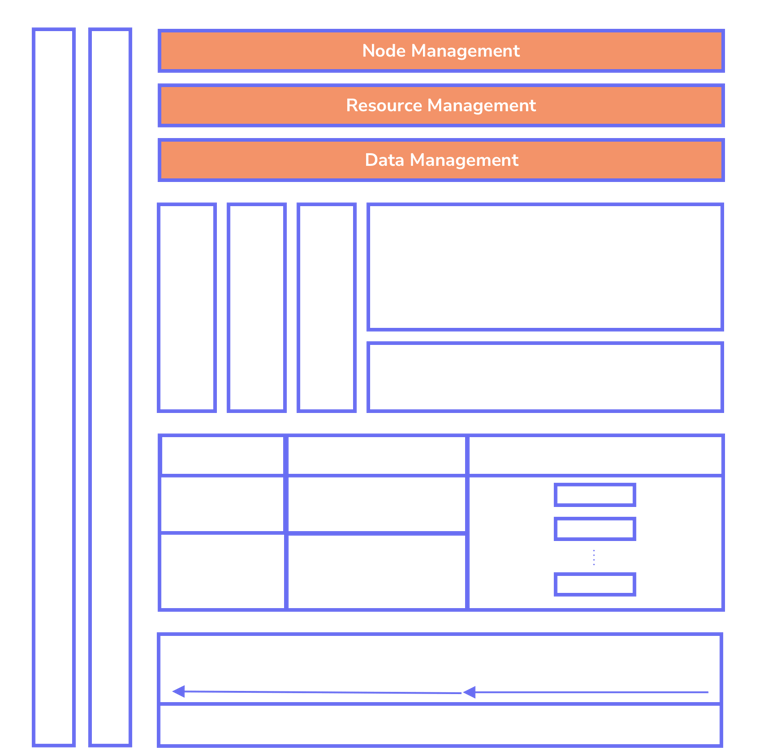
Resource Management
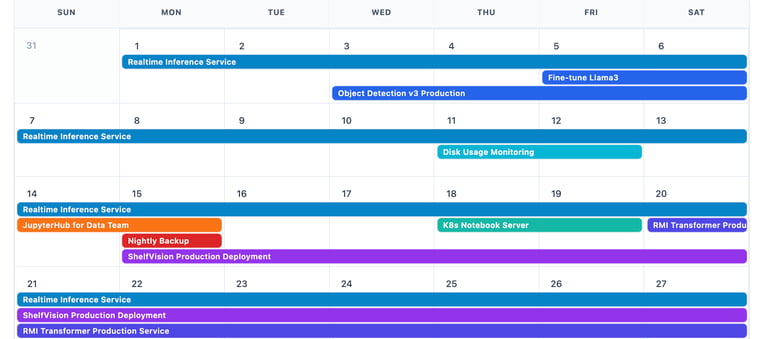
We have built node exporters that can be installed on each server. Through our exporters, we manage and orchestrate the servers. To increase operability and efficiency between servers and training jobs, it is necessary to install a Kubernetes cluster if one does not already exist. We monitor resources such as CPU, GPU, memory, GPU memory, and storage read/write throughput. AI engineers can book and prioritize the resources required for training via our platform, receiving alerts if the monitored metrics exceed thresholds.
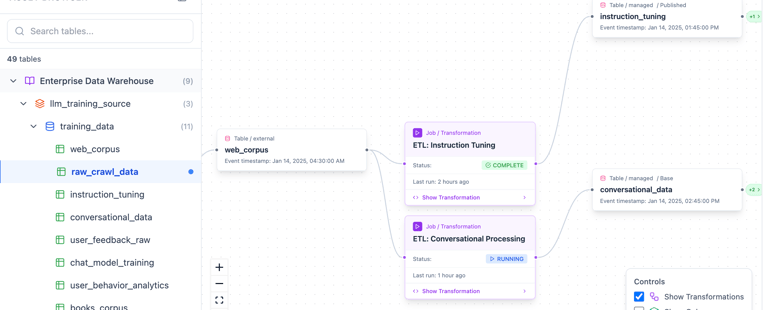
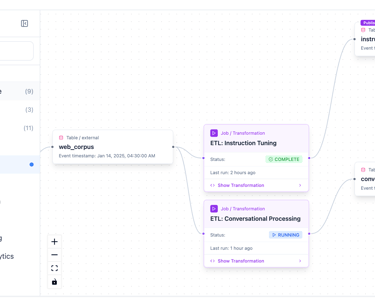
Data Management
We will handle data governance and storage management. AI engineers specify the data to be exported for the project, along with its requirements and any necessary transformations for structured or unstructured data. For instance, in a chatbot project, our transformation job can convert text into a series of question-answer pairs needed for training jobs. Once the requirements are met, wrappers are prepared for data serving in API, stream, and batch formats.
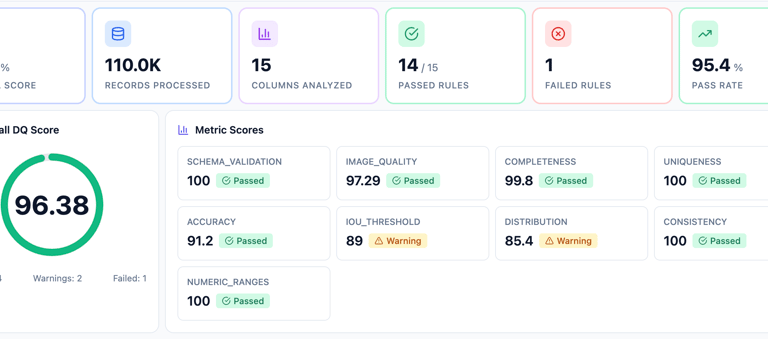
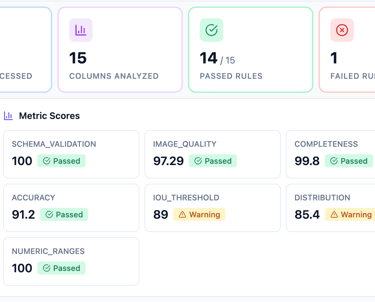
Infrastructure Management
One of our core strengths is enabling enterprises to adopt a hybrid approach by seamlessly integrating cloud and on-premises infrastructure. We provide support for deploying vector databases, data ingestion pipelines, model training, and model serving across diverse environments. Our automation layer, built on top of Kubernetes clusters, ensures efficient and streamlined infrastructure management.
AI catalysts are essential for every data-driven company
Unlock the full potential of shipping secure AI products
Driving innovation with AI for global business excellence
Thunder AI Inc. © 2026. All rights reserved.

LLMOPS Platform